【完全ガイド】Ollamaの使い方|インストールからCLI・GUI操作まで徹底解説(低スペPCでも動くローカルAI)

ローカルでAIを動かしてみたいけど、「難しそう」と感じていませんか?
実は、Ollamaを使えば初心者でも簡単にローカルAI環境を構築できます。GUIで直感的に操作することも、コマンドで細かく設定することも可能です。
この記事では、Ollamaのインストールから使い方、モデル選び、よくあるトラブルの対処法までを分かりやすく解説します。
低スペックPCでも動く構成なので、これからローカルAIを始めたい方はぜひ参考にしてください。
目次
Ollamaとは?
Ollamaは、ローカル環境で大規模言語モデル(LLM)を動かすためのツールです。
通常、AIはクラウド経由で利用されますが、Ollamaを使えば自分のPC内でAIを実行できます。
これにより、以下のようなメリットがあります。
✅ 完全無料で利用できる
✅ オフラインでも動作する
個人開発や検証用途に適した環境を構築することができます。
Ollamaで構築するローカルAI環境の全体像
Ollamaを使った環境は以下のような構成になります。
↓
Ollama
↓
AIモデル
すべての処理がPC内で完結するため、外部サービスに依存しないのが特徴です。
Ollamaを使う前の準備(必要スペックと注意点)
スムーズに導入するために、事前に環境を確認しておきましょう。
最低限の推奨スペック(とりあえず動くレベル)
| OS | Windows 10/11 (WSL2使用可), macOS, またはLinux |
| CPU | 4コア以上(Intel i5 / Ryzen 5クラス) |
| RAM (メモリ) | 8GB |
| GPU (グラボ) | なしでもOK(CPUのみで計算可能) |
| ストレージ | SSD 20GB以上 |
この構成では、軽量モデルを動かせるが、めちゃくちゃ遅い。
実用最低ライン
| OS | Windows 10/11 (WSL2使用可), macOS, またはLinux |
| CPU | 6〜8コア |
| RAM (メモリ) | 16GB |
| GPU (グラボ) | なしでもOK(CPUのみで計算可能) |
| ストレージ | SSD 50GB以上 |
この構成なら、軽量モデルが現実的な速度で動く。チャット用途ならストレス少なめ。

快適ライン
| OS | Windows 10/11 (WSL2使用可), macOS, またはLinux |
| CPU | 8コア以上 |
| RAM (メモリ) | 32GB |
| GPU (グラボ) | VRAM 8GB以上(RTX 3060など) |
| ストレージ | SSD 100GB以上 |
この構成なら、7B~14Bが快適に動くゾーン。※実際に動かしてみないと体感は分からないので注意

モデルサイズ別の目安
| モデル | 必要メモリ | 体感 |
|---|---|---|
| 7B | 8〜16GB | 最低限 |
| 13B | 16〜32GB | 実用 |
| 30B以上 | 32GB〜 | 上級者(重い) |
あくまで目安なので、実際に動かしてみるのが一番です。

Ollamaのインストール方法
公式サイトからインストーラーをダウンロードし、通常通りインストールします。
公式サイト: https://ollama.com
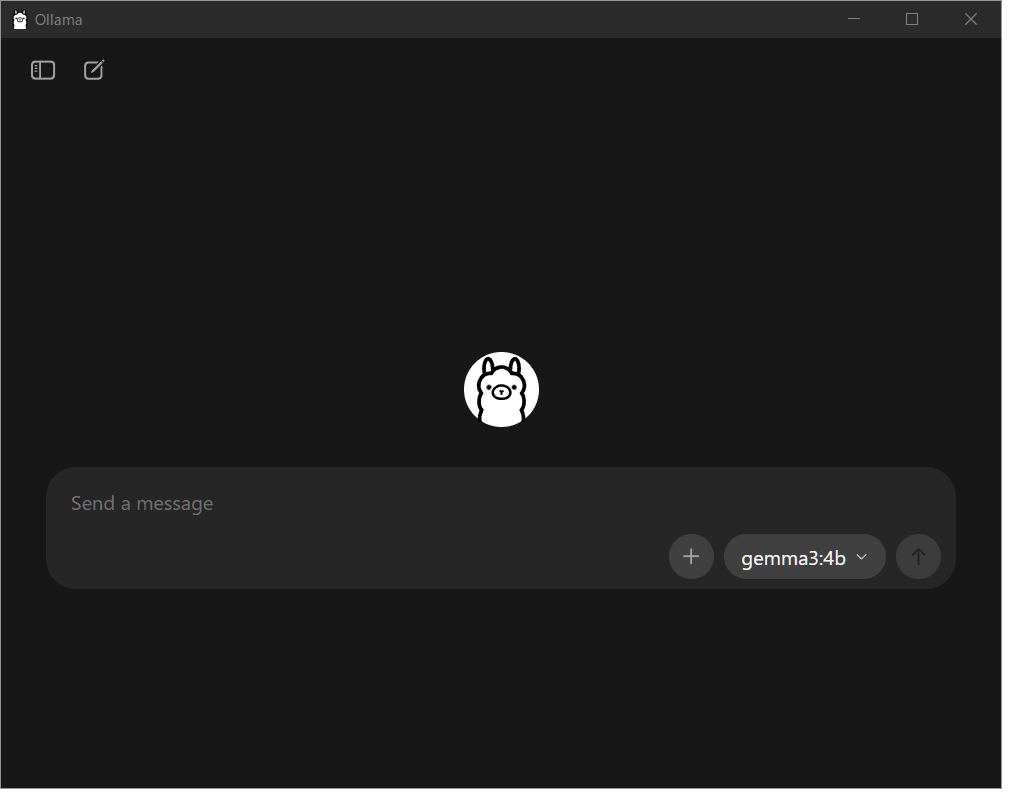
起動すると下画像のような画面になります。
GUI版Ollamaの使い方(初心者向け)
初心者の方は、まずGUIで使うのがおすすめです。
GUIでは、モデル選択やチャットをクリック操作で行えます。
モデル選択画面で任意のモデルをダウンロードできます。ダウンロードはバックグラウンドで実行され、軽量なモデル(1B〜3Bクラス)なら数分、標準的な7Bクラスなら5分〜10分程度(回線速度によります)で完了します。
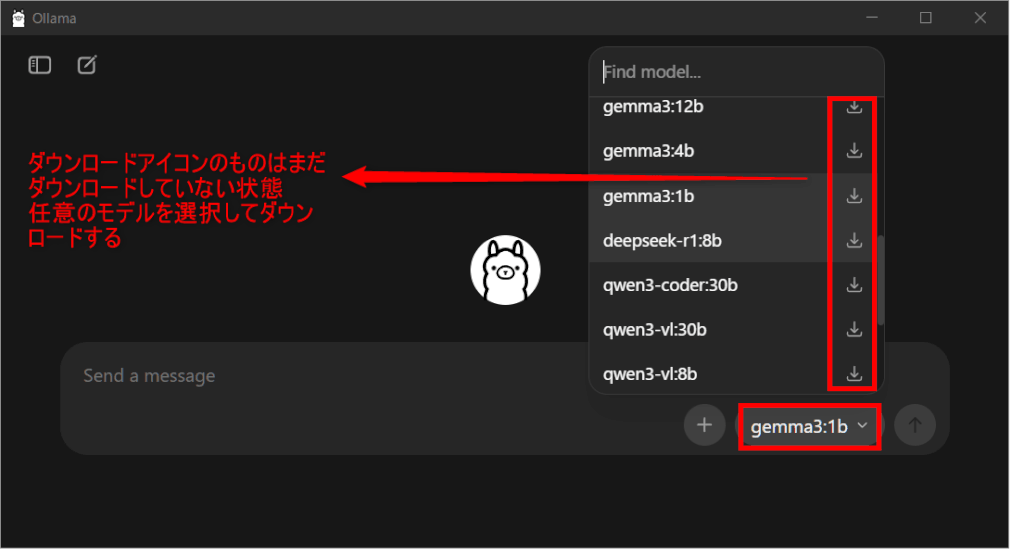
ダウンロードが始まらない場合は、モデルを選択して質問や挨拶などを入力したあとにキーボードのEnterを押すと自動的にモデルがダウンロードされます。
モデルがダウンロードされると質問の返答が表示されます。
コマンド操作が不要なため、直感的にAIを使い始めることができます。
コマンドで使うOllamaの基本操作
より自由に操作したい場合はコマンドを使います。
ターミナル(コマンドプロンプトやPowerShell)でコマンドを実行します。
基本コマンドは以下です。使い方は次の項で説明します。
モデルのダウンロード
ollama pull モデル名
モデルダウンロード + 即起動(チャット開始)
ollama run モデル名
モデルを削除
ollama rm モデル名
モデルの確認
ollama list
モデルの詳細情報を表示
ollama show モデル名
Ollamaの使い方|AIを実行する方法
モデルを準備したら、実際にAIを動かしてみましょう。
まずはPowerShellを起動します。スタートメニューにある「Windows PowerShell」から起動するか、キーボードの + Rで「ファイルを指定して実行」にPowerShellと入力してEnterで起動します。
PowerShell画面でコマンドを入力したあとEnterを押すと実行されます。
PowerShellで以下のコマンドを実行します。
ollama run モデル名
例えばモデルがqwen3:0.6bの場合は、
ollama run qwen3:0.6b
と入力して実行します。
あとは>>>Send massageと表示されているところにプロンプト(指示)を入力してEnterを押すだけです。
Ollamaの終了方法
PowerShellやターミナルでOllamaのチャットを終了する方法は、主に4つあります。
コマンドで終了する(一番おすすめ)
チャットの入力欄に/byeもしくは/exitと入力してEnterで終了。
キーボードショートカットキーで終了する
Ctrl + Dで終了。多くのターミナルソフトで「入力の終了」を意味する標準的なショートカットです。
Ctrl + Cで強制終了。AIが回答の途中で止まらなくなった時などにも使えます。
プログラムごと閉じる
ウィンドウ右上の 「×」ボタン でPowerShell自体を閉じてしまっても問題ありません。Ollamaの本体(サーバー)はバックグラウンドで動き続けているので、次にPowerShellを開いた時もすぐに続きから始められます。
Ollamaを完全に終了する
Ollamaは基本的にバックグラウンドで待機しています。サービスとプロセスも含め、完全停止したい場合は次のコマンドを実行すれば完全に終了できます。
Stop-Service -Name "Ollama" -ErrorAction SilentlyContinue Get-Process -Name "ollama*" | Stop-Process -Force -ErrorAction SilentlyContinue
また、タスクバー右下のシステムトレイ(隠れているインジケーター)にあるOllamaのアイコン(ラマのマーク)を右クリックして「Quit Ollama」からも完全に終了することができます。
モデル保存先を変更する方法(Cドライブ対策)
デフォルトではOllamaのモデルインストール先はCドライブです。
モデルにもよりますが、容量が大きいものもあるので、ストレージを圧迫しないために保存先を変更することができます。
Windowsのユーザー環境変数に「OLLAMA_MODELS_PATH」を設定することで、保存先を変更できます。
やり方ですが、PowerShellで実行するのが早いので、ステップ形式で書いておきます。
※PowerShellは管理者権限での実行を推奨。
スタートメニューにある「Windows PowerShell」を右クリックから「管理者権限で実行」で起動できます。
PowerShellでコマンドを実行する時は、コマンドを入力してキーボードのEnterで実行します。
ステップ① Ollamaを完全に終了する
まず、設定を反映させるためにOllamaを閉じます。
次に、タスクバー右下のシステムトレイ(隠れているインジケーター)にある Ollamaアイコン(ラマのマーク)を右クリック。
「Quit Ollama」 を選択して完全に終了させます。※Ollamaをバックグラウンドプロセスを含めて完全に停止しないと設定が反映されないので注意
念のためにPowerShellで次のコマンドを実行。
Stop-Process -Name "ollama app" -Force -ErrorAction SilentlyContinue Stop-Process -Name "ollama" -Force -ErrorAction SilentlyContinue
完全停止しているかを次のコマンドで確認。
Get-Process ollama -ErrorAction SilentlyContinue
何も表示されなければ完全停止しています。何か表示される場合はまだ完全停止できていません。
要因と考えられるのは、Windowsサービスやタスクスケジューラーに登録されているケースです。その場合は次のコマンドで対処します。
Windowsサービスを停止。
Stop-Service ollama
タスクスケジューラーに登録されているタスク名を表示。登録されていなければ何も表示されない。
Get-ScheduledTask | Where-Object { $_.TaskName -like "*ollama*" }
タスク名を入力して実行。
Stop-ScheduledTask -ここにタスク名を入力 "ollama"
これで完全停止できます。通常はシステムトレイのアイコンを右クリックして終了すれば完全停止しているはずです。
ステップ② 現在のモデル保存先を確認する
デフォルトの保存先は以下です。
C:\Users\<ユーザー名>\.ollama\models
現在のパスを確認。
$env:OLLAMA_MODELS
ステップ③ Dドライブに新しいフォルダを作成してモデルをコピー
Dドライブの好きな場所にモデルを格納するためのフォルダを作成して、そこにCドライブにあるモデルをコピーします。
例:D:\OllamaModelsの場合
次のコマンドを実行。
New-Item -ItemType Directory -Path "D:\OllamaModels" -Force robocopy "$env:USERPROFILE\.ollama\models" "D:\OllamaModels" /E /MOVE /NP
※/MOVEでコピー後に元ファイルを削除します。コピーのみにしたい場合は/MOVEを外してください。
ユーザー環境変数を設定する
次のコマンドを実行。
[System.Environment]::SetEnvironmentVariable("OLLAMA_MODELS", "D:\OllamaModels", "User")
ステップ④ Ollamaを再起動して確認
環境変数の反映にはターミナルの再起動が必要です
PowerShellを一旦閉じて、再起動後に次のコマンドを実行。
$env:OLLAMA_MODELS
D:\ollama\modelsと表示されれば完了です。次回からモデルをダウンロードした時はD:\ollama\modelsに保存されます。
ローカルAIモデルの選び方(最重要ポイント)
ローカルAIでは、モデル選びが最も重要です。
低スペックPCでは以下のようなモデルを選択します。
- 小さいモデル(2B〜4B)
- メモリ消費が少ない
- 推論速度が速い
おすすめの軽量モデル(低スペックPC向け)
実際に使いやすいモデルで、代表的な軽量モデルは以下です。
- Phi-3 Mini(バランス型)
- gemma:2b(高速)
- qwen3:0.6b(超軽量&爆速)
| モデル | サイズ | RAM目安 | 得意分野 | 特徴 |
|---|---|---|---|---|
| qwen3:0.6b | 0.6B | 3~4GB | AIエージェント / 自動化 / CLI補助 | 超軽量・高速 |
| TinyLlama | 1.1B | 4GB | ボット / 自動化 | 超軽量 |
| DeepSeek Coder 1.3B | 1.3B | 4GB | コーディング | 小さいのにコード強い |
| Moondream | 1.4B | 4GB | 画像解析 | 画像対応 |
| Gemma 2B | 2B | 6GB | チャット / 要約 | とても軽い |
| Phi-3 Mini | 3.8B | 8GB | 汎用チャット / 推論 / 簡単なコード | 軽量で最も賢い |
RAM 8GB以下: 0.6B 〜 3B クラス
RAM 16GB以上: 7B 〜 14B クラス
CPUの性能、メモリ容量によって体感も違ってきますので、まずは軽いモデルから試してみてください。
Ollamaの最新モデルを確認する方法
Ollamaは非常に更新が早く、2026年現在も新しいモデルが次々と追加されています。
モデルのチェックはOllama公式サイトから確認できます。
公式サイト: https://ollama.com/library
Ollamaが遅い原因と対処法
Ollamaを使っていて「遅い」と感じる場合、その原因のほとんどはモデルサイズにあります。
特に初心者がやりがちなのが、「高性能そうだから」という理由で大きなモデルを選んでしまうことです。
しかし、ローカル環境ではモデルが大きいほど処理負荷が増え、結果的にレスポンスが遅くなります。
主な原因は以下の通りです。。
- モデルが重すぎる
- CPUが処理しきれてない
- メモリ不足
対処法はシンプルで、軽いモデルに変えるだけです。これが一番効果あります。
また、バックグラウンドで動いているアプリを停止することで、多少の改善が見込めます。
低スペックPCの場合は、なるべく他のアプリを起動していない状態でOllamaを使った方が良いです。
実際に使って分かったこと
私のPCスペックはかなり古いPCなので低スペックです。
試しにqwen2.5-coder:7bをインストールして使ってみましたが、レスポンスが異常に遅く使い物になりませんでした。
RAMは16GBありますが、CPUがネックとなっているようです。
そこで、qwen3:0.6bをインストールしてみたところ、快適に動作しました。超軽量モデルだけあってレスポンスも速いです。
軽いモデルを使えば、普通にコード書かせたり説明をさせたりできます。しかしモデルが重くなると、一気にストレスが増えます。
繰り返しになりますが、結論としては、CPUが古い場合やメモリが少ない場合はとにかく軽量モデルを選ぶことです。
あと、モデルをダウンロードしたらGUIのOllamaから選択できるようになるので、正直、GUIからチャットした方が早いです。
まとめ
Ollamaはモデルダウンロード時には通信環境が必要ですが、一回ダウンロードしてしまえば完全オフラインで使えるのが最大の魅力です。
データが送信される心配もなければ、API制限もなくAIを使えて非常に便利です。
別記事では、Pythonを使ったAIエージェントの作り方や、初心者向けに簡易的なAIチャットの作り方も書いていますので、是非読んでみてください。





